 |

Startseite > Sprachen > Wissenswertes
Wissenswertes über Sprachen
Betonung
Bezugssysteme
Diakritische Zeichen
Dialekt oder Sprache?
Genus
Lauttreue
Namen
Sprache und Denken
Sprachfamilien
T-/V-Formen
Vokale und Konsonanten
Vokalharmonie
Zählsysteme
Literatur
Betonung: Wenn man nicht gerade eine Tonsprache wie Chinesisch lernt, muss man sich beim Lernen einer Fremdsprache meist damit auseinandersetzen, welche Silbe eines Wortes betont wird. Dabei haben unterschiedliche Sprachen natürlich unterschiedliche Konzepte: Polnisch, Italienisch und Spanisch betonen mit einigen Ausnahmen die vorletzte Silbe, Französisch die letzte, was vermutlich damit zusammenhängt, dass die ursprünglich letzte Silbe der romanischen Schwestersprachen in der Aussprache weggefallen ist. In finno-ugrischen Sprachen wird die erste Silbe betont, was vermutlich dazu geführt hat, dass das auch im Deutschen und Tschechischen der Fall ist. Im Deutschen hat diese Regel jedoch durch Vorsilben und Fremdwörter zahlreiche Ausnahmen bekommen. Damit hat es sich wieder ein wenig dem indogermanischen Urzustand der von Wort zu Wort verschiedenen („freien“) Betonung angenähert, die es heute z.B. noch im Russischen und Litauischen gibt. In diesen Sprachen ist die Betonung bedeutungsunterscheidend: russisch múka bedeutet „Qual“, muká „Mehl“. In anderen Sprachen wie Baskisch und Türkisch ist die Betonung weniger wichtig und dementsprechend nicht stark ausgeprägt, im Baskischen variiert sie sogar von Dialekt zu Dialekt.
Bezugssysteme: Aus dem Deutschen und den anderen europäischen Sprachen kennen wir die Unterscheidung zwischen „rechts“ und „links“, die aus der Sicht des Sprechers erfolgt („egozentrisch“) und damit von seiner Position abhängig ist. In anderen Sprachen gibt es „geografische“ oder „absolute“ Bezugssysteme, die Himmelsrichtungen, oft beschrieben durch bestimmte Orte des Ursprungsgebietes der Sprache, als Bezug wählen. Eine dritte Gruppe benutzt ausschließlich die Beziehungen von Objekten zueinander. [1]
Diakritische Zeichen: Kein Alphabet (außer der der internationalen Lautschrift IPA) ist darauf ausgerichtet, alle möglichen Laute wiederzugeben. Daher existieren in den meisten Alphabeten Ergänzungen, die die Schreibung von ursprünglich nicht vorgesehenen Lauten möglich machen. Meistens handelt es sich dabei um diakritische Zeichen, die mit den vorhandenen Buchstaben kombiniert werden. Das gilt vor allem für das lateinische Alphabet, das ursprünglich für die Wiedergabe des Lateinischen entwickelt wurde und inzwischen von Sprachen auf der ganzen Welt verwendet wird. Hier gibt es eine entsprechende Vielzahl von diakritischen Zeichen.
Einige Beispiele für diakritische Zeichen und ihre Verwendung (V=bei Vokalen, K=bei Konsonanten):
- Akut ´ (V/K): veränderte Aussprache (frz. allé, poln. Kraków), abweichende Betonung (span. información), langer Vokal (ung. János), Hervorhebung von Wörtern (ndl. één). Eine Sonderform des Akuts ist die Kreska, die im Polnischen palatalisierte Buchstaben kennzeichnet (Świnoujście).
- Brevis ̆ (V/K): veränderte („kurze“) Aussprache (esp. ankaŭ, türk. yağmur)
- Cedille ¸ (K): [s]-Aussprache vor a, o, u (frz. ça), Zischlautaussprache (türk. çocuk)
- Gravis ̀ (V): veränderte Aussprache (frz. chère), abweichende Betonung (ital. città), Unterscheidung gleich lautender Wörter (frz. où, ital. sì)
- Haček ̌ (V/K): Zischlautaussprache (lit. aš, tschech. čtvrtek), weiche Aussprache (tschech. Plzeň)
- Makron ̄ (V): langer Vokal (lat., lett. tū)
- Ogonek ̨ (V): nasaler Vokal (poln. Dąbrowski), langer Vokal (lit. laikų)
- Ring ̊ (V): veränderte („o-haltige“) Aussprache (dän. på), langer Vokal (tschech. můstek)
- Tilde ˜ (V/K): [ɲ]-Aussprache (span. español), nasaler Vokal (port. são)
- Trema ¨ (V): getrennte Aussprache von Vokalen (frz. maïs)
- Umlaut ¨ (V): veränderte Aussprache (dt. Bücher, finn. neljä), grafisch identisch mit dem Trema. Im Dänischen und Norwegischen wird ø statt ö geschrieben.
- Zirkumflex ˆ (V/K): langer Vokal (frz. chêne), veränderte Aussprache (esp. ĉu)
Im Zeitalter des Computers stellen diakritische Zeichen ein gewisses Problem dar: Zum einen sind die Buchstaben mit ihnen nicht in jedem Zeichensatz vorhanden bzw. befinden sich in verschiedenen Zeichensätzen an verschiedenen Stellen. Missverständnisse wie „Solidarno??“ oder „Solidarnoœæ“ sind also vorprogrammiert. Zur Vermeidung kann man entweder die diakritischen Zeichen weglassen („Solidarnosc“) oder einen Zeichensatz wie Unicode („Solidarność“) oder UTF-8 verwenden. Ersteres senkt die Lesbarkeit, obwohl die Leser der meisten Sprachen das Weglassen der Zeichen gewohnt sind. Letzteres wird leider immer noch nicht von allen Rechnern und auf allen Systemen korrekt interpretiert.
Interessant ist auch die Einordnung der Buchstaben mit diakritischen Zeichen ins Alphabet: In manchen Sprachen (z.B. Französisch) werden sie wie ihre Pendants ohne Sonderzeichen behandelt, in anderen (z.B. Tschechisch) werden sie in einer eigenen Rubrik nach dem eigentlichen Buchstaben einsortiert. Finnisch und Schwedisch stellen ä und ö ans Ende des Alphabetes. Im Deutschen sind für die Umlaute gleich zwei Sortierungen gebräuchlich: die Behandlung als a, o, u und die als ae, oe, ue. Letztere stellt die bevorzugte Variante zur Vermeidung der diakritischen Zeichen dar und ist damit ein Unikum – „Hauser“, „Baume“ oder „Muller“ werden von deutschen Lesern nicht ohne Weiteres richtig verstanden.
Übrigens gibt es nur sehr wenige Sonderzeichen, die nicht diakritisch sind. Das deutsche ß gehört ebenso dazu wie die Ligaturen æ und œ sowie die isländischen þ und ð, die in der Aussprache dem englischen „th“ entsprechen.
Dialekt oder Sprache? Die Entscheidung, ob ein bestimmtes Idiom ein Dialekt oder eine eigene Sprache ist, ist nicht immer einfach zu treffen. Ein wichtiges Kriterium ist sicher die gegenseitige Verständlichkeit, jedoch kann dies schnell an seine Grenzen stoßen: So gibt es z.B. so genannte Dialektkontinua, in denen sich zwar zwei benachbarte Dialekte nur wenig unterscheiden und auch untereinander verständlich sind, sich jedoch zwei Sprecher von entgegengesetzten Enden des Kontinuums nicht verstehen können. Solche Kontinua gibt es z.B. im romanischen Sprachgebiet von Sizilien über Südfrankreich bis Portugal oder im germanischen Raum von der Schweiz bis in die Niederlande.
In der Praxis entscheiden meist noch andere Kriterien als die gegenseitige Verständlichkeit über die Einteilung als Sprache oder Dialekt. Ein wichtiger Faktor ist dabei die Normierung: Wenn es eine einheitliche Rechtschreibung und Grammatik und auch eine eigenständige Literatur gibt, so handelt es sich in der Regel um eine Sprache. Aber auch politische Faktoren spielen eine Rolle: So werden oft Sprachen in verschiedenen Ländern verschieden benannt oder vom Dialekt zur Sprache „befördert“ (Beispiel Serbisch/Kroatisch oder Luxemburgisch). Alle diese Faktoren fördern (sozusagen als „faktische Kraft des Normativen“) wiederum die eigenständige Entwicklung von Sprachen, so dass auch durch den bloßen Vergleich der Idiome die Unterschiede mit der Zeit immer größer werden.
Es gibt auch weniger ernst gemeinte Definitionen wie zum Beispiel den dem Linguisten Max Weinreich zugeschriebenen alten Witz: „Eine Sprache ist ein Dialekt mit einer Armee und einer Marine“. Interessant ist auch, dass Reiseführer Touristen oft den Tipp geben, ein Minimum einer Sprache zu beherrschen, aber sich besser nicht an Dialekten zu versuchen.
Genus: Nicht nur haben die meisten Lebewesen ein natürliches Geschlecht, sondern auch viele Sprachen ein grammatisches Geschlecht oder Genus. Das muss natürlich nicht immer mit dem natürlichen Geschlecht übereinstimmen (das Mädchen, die Geisel, der Zwilling, ...). Und Gegenstände haben oft ein grammatisches Geschlecht, obwohl es bei ihnen eigentlich keinen Sinn ergibt und auch keine zusätzliche Information enthalten ist: Vom rein logischen Gesichtspunkt spräche nichts dagegen, *der Messer, *das Gabel und *die Löffel zu sagen. Entsprechend schwierig ist es für Ausländer, eine solche Sprache zu lernen – wobei manche Sprachen (z.B. die meisten romanischen und slawischen Sprachen) es dem Lernenden dadurch einfach machen, dass das Genus an der Endung zu erkennen ist.
Unterschiedlich ist auch die Anzahl der Genera in den Sprachen: Deutsch, Latein und slawische Sprachen haben Maskulinum, Femininum und Neutrum, romanische Sprachen kennen das Neutrum nicht. Das Niederländische hat Maskulinum und Femininum weitgehend zusammengefasst (Fachausdruck „Utrum“) und bezeichnet dies mit dem Artikel de, im Gegensatz zum Neutrum mit dem Artikel het. Im Englischen und im Afrikaans wird nur bei den Pronomen zwischen den drei Genera unterschieden, als Artikel gibt es nur the bzw. die. Im Finnischen und Estnischen schließlich werden Genera überhaupt nicht unterschieden, hier gibt es nur ein Pronomen für alle Menschen sowie eins für alle Gegenstände. Auf der anderen Seite ist das Genus nur der Spezialfall des Nominalklassen-Systems, das in manchen Sprachen bis zu zehn Einteilungen z.B. für die Form von Gegenständen kennt. Wie in unserem Genussystem auch, sind die Einteilungen dabei manchmal kurios: Im australischen Gurrgoni fällt das Wort für „Flugzeug“ in die Klasse für Gemüse. Grund ist vermutlich die Assoziationskette „Gemüse“ > „Holz“ > „Kanu“ > „Transportmittel“ > „Flugzeug“ – ähnliche Assoziationen werden auch bei der Entstehung der Genera etwa im Deutschen vermutet. [2]
Natürlich hat auch das Aufkommen des Feminismus die Sprache(n) beeinflusst. So schreiben im Deutschen manche Menschen stets beide Formen: Lehrerinnen und Lehrer, Lehrer/-innen oder LehrerInnen oder fügen noch ein Zeichen für Menschen hinzu, die sich keinem Geschlecht zugeordnet fühlen (Lehrer*innen). Andere Linguisten sind dagegen der Meinung, dass mit dem Wort „Lehrer“ zunächst einmal ein lehrender Mensch, gleich welchen Geschlechts, gemeint und das Wort „Lehrerin“ nur ein Spezialfall davon ist. Welchem „Lager“ man auch immer anhängt: Immer besteht die Gefahr von Stilblüten und Uneindeutigkeiten („Angela Merkel ist die bisher beste Bundeskanzlerin“). Andere Sprachen haben andere Streitfragen: So werden im Englischen heute für Subjekte ohne bestimmtes Genus (wie person) meistens die Pronomen der 3. Person Plural verwendet, um „he/she“ zu vermeiden: I miss you like a child misses their blanket. Romanische Sprachen benutzen manchmal das „@“ als „Verschmelzung“ von a und o: ¡Hola amig@s!. In uralischen Sprachen wie dem Finnischen gibt es mangels Genus derartige Probleme so gut wie gar nicht: Hän on minun paras ystävä kann sowohl „Er ist mein bester Freund“ als auch „Sie ist meine beste Freundin“ bedeuten.
Lauttreue: In den wenigsten Sprachen, die mit Buchstabenschriften geschrieben werden, entspricht ein Buchstabe immer genau einem Laut und umgekehrt. Das hat verschiedene Gründe: Zum einen ist es sinnvoll, ähnliche Laute (z.B. langer/kurzer oder offener/geschlossener Vokal) durch denselben Buchstaben auszudrücken. Zum zweiten nutzen die allermeisten Sprachen ein Alphabet, das ursprünglich nicht für diese Sprache entwickelt wurde. Dieses Problem wird häufig mit Buchstabenkombinationen (Di- oder Trigraphen) oder diakritischen Zeichen gelöst. Dadurch lässt sich eine beträchtliche Lauttreue erreichen, so wird z.B. der Laut [ʃ] im Deutschen mit einigen Ausnahmen durch „sch“ und im Tschechischen immer durch „š“ wiedergegeben. Ebenso gilt, dass diese Buchstaben auch immer [ʃ] ausgesprochen werden (Ausnahmen wie Werkschor bestätigen diese Regel).
Zum dritten verändern sich Sprachen im Laufe der Zeit, so dass Ausspracheveränderungen entstehen, die nicht automatisch zu einer Anpassung der Schreibung führen. Abgesehen davon gibt es natürlich auch verschiedene Aussprachen in verschiedenen Varianten einer Sprache (wie z.B. bei den deutschen Wörtern König oder Post).
Viertens importieren Sprachen Wörter aus anderen Sprachen. Ob die Schreibweise dabei angepasst wird, richtet sich ebenfalls nach der Lauttreue der Sprache. Im Deutschen sind „Theater“ oder „Philosophie“ ohne th bzw. ph für viele undenkbar, während teatro im Italienischen oder filosofie im Niederländischen selbstverständlich sind.
Leider sind nicht alle Sprachen so konsequent. Bei den Vokalen fehlt vor allem oft eine Markierung der Länge; Konsonanten werden oft geschrieben, obwohl sie stumm sind. Das Englische ist hier ein besonderes Negativbeispiel, weil auch die Aussprache der Vokale stark abweicht und weder von der Aussprache auf die Schreibung noch umgekehrt geschlossen werden kann. So können etwa bow oder tear auf je zwei Arten mit unterschiedlicher Bedeutung ausgesprochen werden. Umgekehrt gibt es für [nju:] die Schreibweisen new und knew. Im Französischen lässt sich zwar fast immer die Aussprache zur Schreibung eindeutig bestimmen, jedoch nicht umgekehrt ([o:] kann etwa eau, oh oder haut geschrieben werden). In beiden Sprachen hat die Abweichung übrigens hauptsächlich den dritten der genannten Gründe, die Schreibung orientiert sich also an einer früheren Aussprache. Im Englischen wurden sogar in Anlehnung an lateinische Wörter Buchstaben eingefügt, die nie oder nicht mehr gesprochen wurden: das s in island und das b in doubt sind Beispiele dafür.
Auch im Irischen ist die Laut-Buchstaben-Zuordnung kompliziert, was unter anderem am Prinzip der „Einrahmung“ von Konsonanten liegt (siehe unter „Vokalharmonie“). Besonders lautgetreu sind dagegen z.B. das Finnische und das Tschechische. Eine Zuordnung von Konsonanten zu ihrer Schreibweise in verschiedenen Sprachen habe ich ebenfalls auf dieser Website veröffentlicht.
Namen: Wenn eine Stadt, eine Region oder ein Volksstamm an der Grenze mehrerer Sprachgebiete liegt oder international bedeutend ist, wird natürlich in mehreren verschiedenen Sprachen davon geredet, und jede Sprache wendet ihre eigenen Verschleifungsmechanismen an: München/Munich, Wien/Vienna/Vienne. Manchmal wird auch nur, wie bei London und Paris, die Aussprache an die jeweilige Laut-Buchstaben-Zuordnung angepasst. Ein Spezialfall ist die Übersetzung von Namen, die man manchmal nicht mehr erkennen kann (z.B. haben frz. Lille = ndl. Rijsel beide das jeweilige Wort für „Insel“ als Ursprung).
Ein ganz anderer Fall ist das Beispiel Dublin: Der englische, auch in Deutschland gebräuchliche Name geht auf das irische „Dubhlinn“ = „schwarzer Sumpf“ zurück, während der Name im heutigen Irisch Baile Átha Cliath (gesprochen ungefähr „Balja Klier“) = „Stadt an der Hürdenfurt“ lautet. Der Grund ist, dass die beiden Orte Dubhlinn und Baile Átha Cliath zu einer Siedlung zusammen gewachsen sind und jede Sprache einen der Namen übernommen hat.
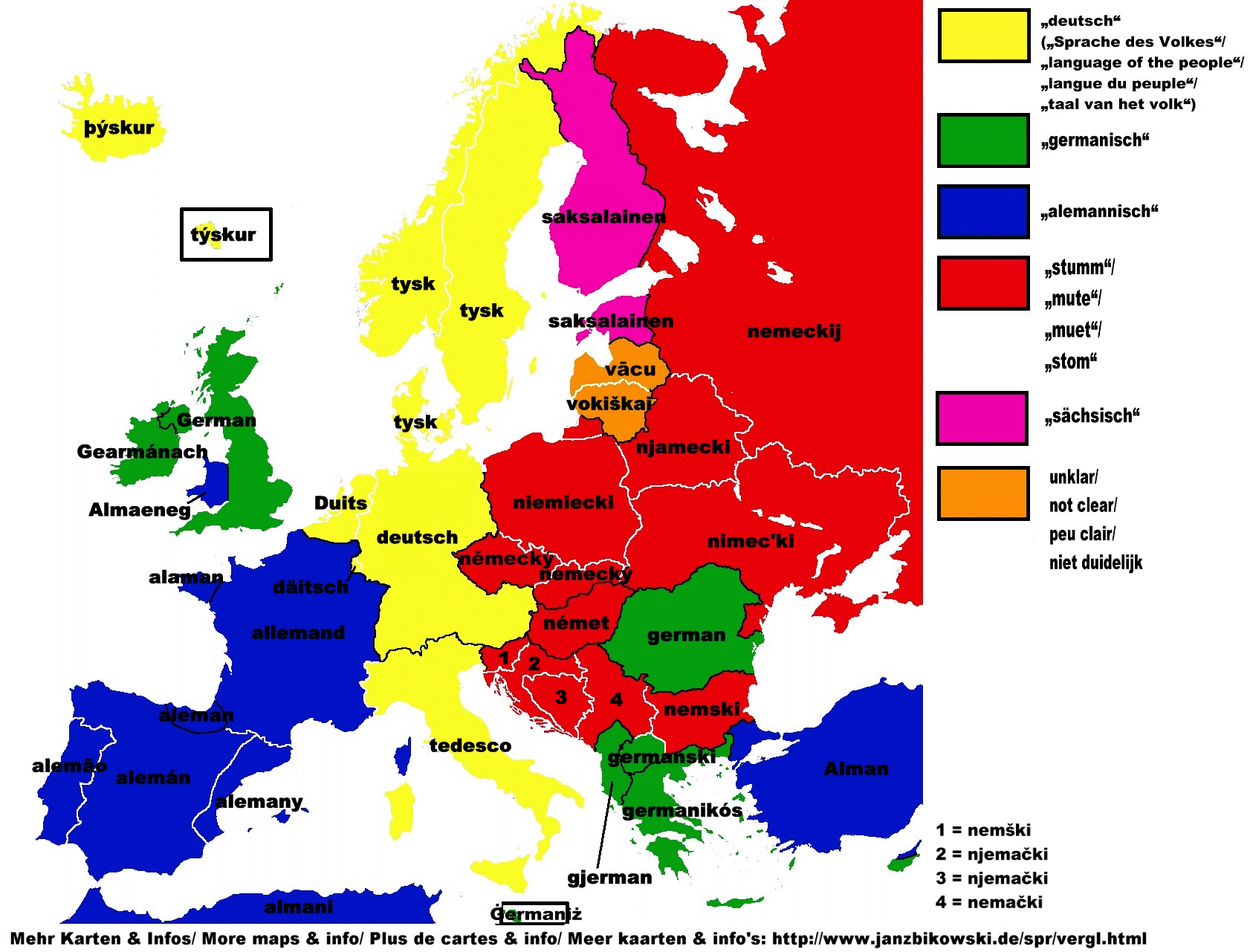
Die dritte Möglichkeit ist, dass verschiedene Völker ein und denselben Ort einfach verschieden benennen. Ein Beispiel dafür ist Bromberg/Bydgoszcz. Der deutsche Name kommt von „Brahenburg“, weil die Stadt am Fluss Brahe (polnisch Brda) liegt. Der polnische Name lautete ursprünglich Bydgost, wobei ich leider nicht herausgefunden habe, wo dieser Name herkommt. Die verschiedenen Wörter für „deutsch“ in den verschiedenen Sprachen gehören auch in diese Kategorie: die Briten sahen in uns Germanen, die Franzosen Alemannen, die Finnen Sachsen und die Slawen die „Stummen“, also des Slawischen nicht Mächtigen (siehe dazu auch die Karte).
Ob man einen Ort mit dem Namen in einer örtlichen Sprache (Endonym, z.B. Brussel oder Bruxelles) oder in einer Fremdsprache (Exonym, z.B. Brüssel oder Brussels) benennen soll, ist häufig Gegenstand politisch-linguistischer Debatten. Auf der einen Seite kann die Verwendung eines Exonyms als Einmischung in die Belange des jeweiligen Landes, je nach historischer Situation auch als Kolonialismus (z.B. in Indien) oder Revisionismus (z.B. in Polen) gesehen werden. Auf der anderen Seite geht ein Exonym meistens leichter von den Lippen (z.B. „Swinemünde“ im Vergleich zu „Świnoujście“). Die Regelungen in den Medien, aber erst recht im allgemeinen Sprachgebrauch, sind hier nicht eindeutig. Viele Exonyme kommen auch im Laufe der Zeit oder durch politische Veränderungen außer Gebrauch, wie z.B. die deutschen Ausdrücke Leyden für Lyon und Reval für Tallinn.
Auch Personennamen werden manchmal an verschiedene Sprachen angepasst. Das trifft vor allem zu, wenn historische Persönlichkeiten in mehreren Ländern gewirkt haben: Franz Liszt/Liszt Ferencz, Nikolaus Kopernikus/Mikołaj Kopernik. Auch heute noch erfordert die Grammatik mancher Sprachen, dass Namen angepasst werden, was zu für deutsche Ohren kuriosen Formen führen kann wie Steffi Grafová (tschechisch), Gerhards Šrēders (lettisch) oder Kofis Ananas (litauisch).
{kind=link}
Sprache und Denken: Die so genannte Sapir-Whorf-Hypothese bessagt, das die (Mutter-)Sprache das Denken beeinflusst. Darüber ist natürlich viel diskutiert und geforscht worden. Jüngere Untersuchungen belegen, dass es zumindest teilweise einen Einfluss gibt: So fällt es Sprechern einer Sprache mit geografischem Bezugssystem wesentlich leichter, Himmelsrichtungen zu bestimmen als Sprechern einer egozentrischen Sprache. Eine weitere Untersuchung förderte zutage, dass abhängig vom Genus eines unbelebten Objekts in einer Sprache diesem bestimmte Eigenschaften zugeschrieben werden: So sehen Deutsche in einer (femininen) Brücke eher filigrane und vermittelnde Eigenschaften, Franzosen in einem (maskulinen) „pont“ eher starke und kräftige.
Interessant ist auch der Einfluss auf das Farbensehen: Nicht alle Sprachen unterscheiden in ihrem Wortschatz die gleichen Farben. So gibt es etwa im Russischen kein einheitliches Wort für „blau“, sondern man muss sich zwischen sinij „dunkelblau“ und goluboj „hellblau“ entscheiden. Interessanterweise haben die meisten Sprachen am ehesten Wörter für (in dieser Reihenfolge) Schwarz und Weiß, Rot, Grün, Gelb, Blau, was wohl an der Bedeutung der Farben in der Natur liegt. Studien mit Sprechern verschiedener Sprachen haben nun ergeben, dass es deutlich ihnen leichter fällt, Farben zu unterscheiden, wenn es dafür in der eigenen Muttersprache auch verschiedene Wörter gibt.
Dass verschiedene Begriffe in der eigenen Sprache die gedankliche Unterscheidung erleichtern, bedeutet aber nicht, dass es unmöglich ist, Unterschiede wahrzunehmen, die die eigene Sprache nicht macht. So können Sprecher von Sprachen, in denen es nur die Farbwörter „schwarz“, „weiß“ und „rot“ gibt, sehr wohl Grün und Blau unterscheiden oder wir Deutschen den Unterschied zwischen safety und security erkennen, auch wenn auf Deutsch beides „Sicherheit“ heißt. [2]
Sprachfamilien: Die Einteilung von Sprachen in Sprachfamilien ist nicht immer ganz einfach, denn es ist nicht immer klar, ob Ähnlichkeiten auf einer (genetischen) Verwandtschaft, auf dem gegenseitigen Einfluss zwischen zwei Sprachen oder schlicht auf dem Zufall beruhen. Andersherum sind viele Ähnlichkeiten mehrere Jahrtausende nach der Trennung der Sprachen voneinander kaum oder gar nicht mehr zu erkennen. So ist z.B. umstritten, ob Koreanisch und Japanisch miteinander verwandt sind und wenn ja, ob sie zur Gruppe der altaischen Sprachen gehören oder nicht. Selbst die Verwandtschaft zwischen mongolischen und Turksprachen innerhalb dieser Gruppe wird von manchen Linguisten angezweifelt.
Ein ähnliches Problem stellt die Frage dar, ob man bekannte Sprachfamilien zu noch größeren Gruppen zusammenfassen kann. So entstand aufgrund bestimmter Ähnlichkeiten (z.B. der Verwendung des Lautes [m] für die erste Person Singular) das Konzept der nostratischen Sprachen als Obergruppe der indoeuropäischen (oder indogermanischen), altaischen und uralischen Sprachen (letztere werden gelegentlich auch als „ural-altaische Sprachen“ zusammengefasst). Je nach Autor werden in diese Gruppe noch weitere Sprachfamilien wie Drawidisch oder Afroasiatisch eingeteilt. Joseph H. Greenberg hat das ganz ähnliche Konzept der eurasiatischen Sprachen entworfen, zu dem außer Indogermanisch, Uralisch und Altaisch (dann mit Koreanisch und Japanisch) beispielsweise noch Eskimo-Aleutisch zählt. Nach diesem Prinzip hat Greenberg auch die indigenen Sprachen Amerikas in drei Gruppen eingeteilt (Eskimo-Aleutisch, Na-Dené und Amerind), wobei Letztere wie die der nostratischen (oder eurasiatischen) Sprachen unter Linguisten umstritten ist. Anerkannter sind Greenbergs Ergebnisse bei den afrikanischen Sprachen, wo man heute von vier Familien ausgeht: Afroasiatisch, Nilo-Saharanisch, Niger-Kongo und die untereinander nicht verwandten Khoi-San-Sprachen.
Demzufolge ist auch die Anzahl der Sprachfamilien nicht klar bestimmbar. Berücksichtigt man die umstrittenen Makrofamilien nicht, so kommt man auf etwa 200 Sprachfamilien sowie so genannte isolierte Sprachen wie Baskisch oder Koreanisch, bei denen man zu keiner Familie eine Verwandtschaft sicher nachweisen kann. 25 dieser Familien haben eine Sprecheranzahl von je mindestens einer Million Menschen und decken insgesamt 99,5% der Menschheit ab. [3] Zu den Schwierigkeiten der Erforschung der Sprachevolution hat der Linguistikprofessor Piotr Gąsiorowski eine Reihe interessanter Blogbeiträge geschrieben. [4]
T-/V-Formen: In vielen Sprachen gibt es wie im Deutschen eine Unterscheidung zwischen höflicher (V-Form) und vertrauter (T-Form) Anrede. Die Bezeichnungen T und V sind vom lateinischen tu (du) und vos (ihr) abgeleitet. Der Gebrauch dieser Formen variiert natürlich nicht nur zwischen verschiedenen Situationen, sondern auch zwischen den Sprachen. So wird der Bewerber z.B. in niederländischen Stellenanzeigen meist geduzt, was in Deutschland in der Regel undenkbar ist. Besonders interessant ist die Verwendung der T-Form (hi) im Baskischen: Sie wird nur zwischen Geschwistern und zwischen engen Freunden des gleichen Geschlechts benutzt. In allen anderen Fällen, also z.B. auch zwischen Eheleuten, gilt der Gebrauch als beleidigend und wird daher normalerweise die V-Form (zu) benutzt. [5]
Auch die Geschichte der T- und V-Formen ist von Sprache zu Sprache unterschiedlich. Oft sind sie im Mittelalter aus der 2. Person Plural entstanden, es gibt aber auch andere Entwicklungen, wie die Verwendung der 3. Person Plural im Deutschen, die aus der Kombination der früheren Anrede mit der 3. Person Singular mit dem „pluralis maiestatis“ entstanden ist. Im Italienischen wird die 3. Person Singular feminin (Lei) verwendet, was daher kommt, dass die Wörter „Ihre Herrschaft/Eminenz/Majestät“ auch im Italienischen feminin sind. Das Niederländische benutzt die eigenständige Form u mit der Verbform der 2. Person Singular, das Polnische die Anrede pan/pani (Herr/Frau) mit der 3. Person Singular. Im Englischen ist die vertraute Form thou fast völlig durch das höfliche you (identisch mit der 2. Person Plural) verdrängt worden. In anderen Sprachen (z.B. in den skandinavischen und dem Finnischen) ist umgekehrt der Gebrauch des „Sie“ weitgehend zugunsten des „Du“ zurück gegangen. Aber auch im Deutschen wird mehr geduzt als noch vor einigen Jahrzehnten, was zeigt, dass der Gebrauch der Formen sich natürlich mit der Zeit verändert. Wesentlich komplizierter sind die Verhältnisse in vielen asiatischen Sprachen, aber auch im Ungarischen gibt es nicht weniger als fünf verschiedene Anredeformen. [6]
Vokale und Konsonanten: Vor allem die Vokalarmut in einer Sprache ist bei benachbarten Völkern häufig Anlass zum Spott oder zu der Feststellung, dass eine Sprache nicht erlernbar sei. Allerdings ist auch hier alles relativ: Während die Sprecher der romanischen Sprachen schon das Deutsche als „Ansammlung von Konsonanten“ sehen, ist für uns das Tschechische extrem vokalarm. Hier stößt man aber auch schon an die Grenze der Definition „Vokal“, denn die Laute [l] und [r] haben durchaus einige Eigenschaften eines Vokals, weshalb sie im Tschechischen „silbenbildend“ oder „vokalisch“ sein können: Vlk zmrzl, zhltl hrst zrn (Der Wolf erfror [und] verschluckte eine Handvoll Korn). Weitere Beispiele für vokalarme Sprachen sind die kaukasischen, in denen 5 Konsonanten hintereinander pro Silbe keine Seltenheit sind. Das Japanische dagegen ist sehr vokalreich: Jede Silbe besteht aus maximal zwei Konsonanten, gefolgt von einem Vokal (Ausnahme ist die Silbe [n]). Zum Vergleich: Deutsche Silben können bis zu 3 Konsonanten vor und 4 hinter dem Vokal haben (Beispiel: Strumpfs).
Nicht unbedingt gesagt ist damit, wie viele verschiedene Vokale es in einer Sprache gibt. Das gesicherte Minimum ist 3, z.B. a, i und u im Grönländischen oder Arabischen, das Maximum liegt bei 24 (!Xũ). Auch das Deutsche kennt mit 15 relativ viele verschiedene Vokale, noch mehr gibt es allerdings in süddeutschen Dialekten wie z.B. dem Österreichischen. Das romanische und damit eher vokalreiche Spanische kommt dagegen mit 5 Unterscheidungen aus. [7]
Bei den Konsonanten können Deutsche wiederum eine Menge im Kaukasus und bei den Buschmännern Südafrikas lernen. Im Kaukasus gibt es viele sehr konsonantenreiche Sprachen (Kabardinisch, Tschetschenisch, Abchasisch und Avar). Sie machen erstens sehr feine Unterschiede zwischen den Konsonanten (z.B. bis zu vier s-Laute mit unterschiedlicher Zungenposition), andererseits haben sie nicht nur stimmhafte und stimmlose Konsonanten wie das Deutsche ([b] und [p], [t] und [d]), sondern auch stark behauchte ([ph], [th]) und ejektive (bei denen die Luft zuerst zurückgehalten wird und dann „herausbricht“). Die südafrikanischen Khoisansprachen kennen dafür viele „Klicklaute“. Das sind Laute, die wie ein Küsschen, ein „Plop“ oder das Schnalzen klingen, das viele Reiter nutzen, um mit ihren Pferden zu kommunizieren. [8]
Vokalharmonie: In vielen Sprachen dürfen Vokale innerhalb eines Wortes nicht beliebig kombiniert werden. Besonders anschaulich ist das in vielen agglutinierenden Sprachen zu beobachten, in denen die anzuhängenden Endungen je nach den Vokalen im Wort verschieden sind: Finnisch (Helsingissä – in Helsinki/Suomessa – in Finnland), Ungarisch (Debrecenben – in Debrecen/magyarban – im Ungarischen) oder Türkisch (İstanbul'da – in Istanbul/Türkiye'de – in der Türkei).
Die Regeln, welche Vokale miteinander „harmonieren“, ist von Sprache zu Sprache verschieden, meistens gehören aber „dunkle“ und „helle“ Vokale jeweils zu einer Gruppe (z.B. im Türkischen a/o/u/ı und e/i/ö/ü). In der Regel stehen innerhalb eines Wortes nur Vokale aus derselben Gruppe, bei Fremd- und Lehnwörtern kann es aber Ausnahmen geben.
Ein etwas anderes Phänomen gibt es im Irischen: Hier darf ein Konsonant immer nur von Vokalen derselben Gruppe (hell oder dunkel) umgeben („eingerahmt“) werden, weil dies markiert, ob der Konsonant „weich“ oder „hart“ gesprochen wird. Das führt dazu, dass manchmal Vokale eingefügt werden, die dann nicht oder kaum hörbar sind (z.B. píosa [pi:sa]). Ein von e oder i eingerahmtes s wird beispielsweise als [ʃ] gesprochen, ein von a,o oder u eingerahmtes als [s]. [9]
Zählsysteme: Auch hier gibt es interessante Aspekte: Zum einen gibt es Sprachen, die gar nicht jede Zahl ausdrücken können, sondern nur die Unterscheidung zwischen „eins“, „zwei“ und „viele“ kennen. Aber auch Sprachen, die mehr Zahlwörter kennen, sind ein interessantes Vergleichsobjekt, denn es unterscheidet sich die Art, wie bei größeren Zahlen die Wörter gebildet werden. Die Zahl 10 spielt dabei wegen der Anzahl der Finger einer große Rolle, so dass meistens bis 10 eigene Zahlwörter verwendet werden. Manchmal haben auch darüber noch einige Zahlen besondere Wörter (im Deutschen bis 12, im Französischen bis 16). Ab 20 bilden die meisten Sprachen ihre Zahlen regelmäßig nach dem Schema „Zehner+Einer“. Eine Ausnahme bilden hier Deutsch, Niederländisch, Dänisch, Tschechisch und Slowenisch, die die Einer zuerst nennen. Auch im Lateinischen ist diese Zählweise möglich, von wo sie eventuell auch ins Deutsche gelangt ist. Interessant ist auch die Benennung der Zehner im Baskischen, wo das Schema 20, 20+10, 2·20, 2·20+10 etc. angewandt wird. Ähnliche Zählweisen gibt es im Bretonischen (2·20, 1/2·100, 3·20, 10+3·20 etc.) und im Französischen (60+10, 4·20, 4·20+10), was auf gegenseitigen Einfluss dieser drei unverwandten Sprachen schließen lässt. Auch Dänisch hat eine Zwanziger-Zählweise: 50=halvtreds „halber Weg zu drei (Zwanzigern)“, 60=tres „drei (Zwanziger)“, analog 70=halvfjerds, 80=firs, 90=halvfems. Ganz regelmäßig zählen dagegen asiatische Sprachen wie Japanisch und Chinesisch: Ab 10 geht es weiter mit „zehn eins“, „zehn zwei“, ..., „zwei zehn“, „zwei zehn eins“ etc. [10]
Literatur
[1] → rinks lechts, DIE ZEIT 01/2005
[2] Guy Deutscher: Im Spiegel der Sprache, C.H.Beck
[3] → Wikipedia: Sprachfamilien der Welt
[4] → And Now for Something Completely Different: Proto-World! (englisch)
[5] → Buber's Basque Page: Basque, by Larry Trask (englisch)
[6] → Wikipedia: T–V distinction (englisch)
[7] David Crystal: Cambridge-Enzyklopädie der Sprache, Zweitausendeins
[8] Danke an Alain für diesen Absatz!
[9] Danke an Alexandre für diesen Absatz!
[10] → Travlang Fremdsprachen für Reisende
↑ Zum Seitenanfang / To Top of Page / Vers haut de la page / Naar begin van pagina ↑



Inhalt: Jan Zbikowski; Design: Nils Müller.
Kontakt; Datenschutz- und andere Hinweise
Letzte Änderung dieser Seite: 01.07.2016
